✅ 강의를 듣고 팁 + 기본 문법에 대한 간단히 정리
프로젝트를 하면서 Querydsl을 사용하는 법에 대해서는 정리했지만, 급한대로 정리한거라 좀 더 자세하게 강의 듣고 정리하려고한다.
인프런 - 김영한 - Querydsl에 대한 정리이다.
✅ 순환참조 방지 @ToString
@ToString(of = {"id", "title", "price"})
public class Product {
private Long id;
private String title;
private int price;
}
✅ 기본 생성자를 막고 싶은데 JPA 스팩상 열어 두어야 할 때 -> PROTECTED 사용!
접근제어자를 활용해서 다른 곳에서 생성자를 사용하지 못하게한다.
private안 되는 이유 : 프록시 클래스에서 super (부모 생성자) 호출 못 하므로 Protected로 해야함.
@NoArgsConstructor(access = AccessLevel.PROTECTED)
class className{
....
}

https://it-jin-developer.tistory.com/60
✅ JPQL이 별로인 이유
코드 작성하는 방식이 Querydsl이 편하다.
JPQL -> 문자열 -> 코드를 실행시점에 오류 발견
QureyDSL -> 자바코드 -> 컴파일 시점에 오류 발견
QueryDSL 코드 작성 예시
@Test
public void startQuerydsl() {
//member1을 찾아라.
JPAQueryFactory queryFactory = new JPAQueryFactory(em); QMember m = new QMember("m");
Member findMember = queryFactory
.select(m)
.from(m)
.where(m.username.eq("member1"))//파라미터 바인딩 처리 .fetchOne();
assertThat(findMember.getUsername()).isEqualTo("member1");
}
- Querydsl은 자바 코드임
- EntityManager로 JPAQueryFactory 생성
- Querydsl은 JPQL 빌더
- JPQL: 문자(실행 시점 오류), Querydsl: 코드(컴파일 시점 오류)
- JPQL: 파라미터 바인딩 직접, Querydsl: 파라미터 바인딩 자동 처리
✅ 기본 Q-Type 활용
Q클래스 인스턴스를 활용하는 2가지 방법
QMember qMember = new QMember("m"); //별칭 직접 지정
QMember qMember = QMember.member; //기본 인스턴스 사용
기본 인스턴스를 static import와 함께 사용
import static study.querydsl.entity.QMember.*;
-> 이렇게하면 그냥 member로 접근 가능
참고 : 같은 테이블을 조인해야하는 경우가 아니면 기본 인스턴스를 사용하자! (안 그러면 Alias충돌)
✅ 결과 조회
- fetch() : 리스트 조회, 데이터 없으면 빈 리스트 반환
- fetchOne() : 단 건 조회
결과가 없으면 : `null`
결과가 둘 이상이면 : `cohttp://m.querydsl.core.NonUniqueResultException` - fetchFirst() : `limit(1).fetchOne()`
- fetchResults() : 페이징 정보 포함, total count 쿼리 추가 실행
- fetchCount() : count 쿼리로 변경해서 count 수 조회
✅ 정렬
/**
* 회원 정렬 순서
* 1. 회원 나이 내림차순(desc)
* 2. 회원 이름 올림차순(asc)
* 단 2에서 회원 이름이 없으면 마지막에 출력(nulls last) */
@Test
public void sort() {
em.persist(new Member(null, 100));
em.persist(new Member("member5", 100));
em.persist(new Member("member6", 100));
List<Member> result = queryFactory
.selectFrom(member)
.where(member.age.eq(100))
.orderBy(member.age.desc(), member.username.asc().nullsLast())
.fetch();
Member member5 = result.get(0);
Member member6 = result.get(1);
Member memberNull = result.get(2);
assertThat(member5.getUsername()).isEqualTo("member5");
assertThat(member6.getUsername()).isEqualTo("member6");
assertThat(memberNull.getUsername()).isNull();
}- desc() , asc() : 일반 정렬
- nullsLast() , nullsFirst() : null 데이터 순서 부여
✅ 전체 조회 수가 필요한 페이징
@Test
public void paging2() {
QueryResults<Member> queryResults = queryFactory
.selectFrom(member)
.orderBy(member.username.desc())
.offset(1)
.limit(2)
.fetchResults();
assertThat(queryResults.getTotal()).isEqualTo(4);
assertThat(queryResults.getLimit()).isEqualTo(2);
assertThat(queryResults.getOffset()).isEqualTo(1);
assertThat(queryResults.getResults().size()).isEqualTo(2);
}주의 : count 쿼리가 실행되니 성능상 주의!
참고: 실무에서 페이징 쿼리를 작성할 때, 데이터를 조회하는 쿼리는 여러 테이블을 조인해야 하지만, count 쿼리 는 조인이 필요 없는 경우도 있다. 그런데 이렇게 자동화된 count 쿼리는 원본 쿼리와 같이 모두 조인을 해버리기 때문에 성능이 안나올 수 있다. count 쿼리에 조인이 필요없는 성능 최적화가 필요하다면, count 전용 쿼리를 별 도로 작성해야 한다.
✅ 집합 함수
/**
* JPQL
* select
* COUNT(m),
* SUM(m.age),
* AVG(m.age),
* MAX(m.age),
* MIN(m.age)
* from Member m
*/
//회원수 //나이 합 //평균 나이 //최대 나이 //최소 나이
@Test
public void aggregation() throws Exception {
List<Tuple> result = queryFactory
.select(member.count(),
member.age.sum(),
member.age.avg(),
member.age.max(),
member.age.min())
.from(member)
.fetch();
Tuple tuple = result.get(0);
assertThat(tuple.get(member.count())).isEqualTo(4);
assertThat(tuple.get(member.age.sum())).isEqualTo(100);
assertThat(tuple.get(member.age.avg())).isEqualTo(25);
assertThat(tuple.get(member.age.max())).isEqualTo(40);
assertThat(tuple.get(member.age.min())).isEqualTo(10);
}- JPQL이 제공하는 모든 집합 함수를 제공한다.
- tuple은 프로덕션과 결과반환에서 설명한다.
✅ GroupBy 사용
/**
* 팀의 이름과 각 팀의 평균 연령을 구해라. */
@Test
public void group() throws Exception {
List<Tuple> result = queryFactory
.select(team.name, member.age.avg())
.from(member)
.join(member.team, team)
.groupBy(team.name)
.fetch();
Tuple teamA = result.get(0);
Tuple teamB = result.get(1);
assertThat(teamA.get(team.name)).isEqualTo("teamA");
assertThat(teamA.get(member.age.avg())).isEqualTo(15);
assertThat(teamB.get(team.name)).isEqualTo("teamB");
assertThat(teamB.get(member.age.avg())).isEqualTo(35);
}groupBy , 그룹화된 결과를 제한하려면 having
...
.groupBy(item.price)
.having(item.price.gt(1000))
...
✅ 조인 - 기본 조인
기본 조인
조인의 기본 문법은 첫 번째 파라미터에 조인 대상을 지정하고, 두 번째 파라미터에 별칭(alias)으로 사용할
Q 타입을 지정하면 된다.
join(조인 대상, 별칭으로 사용할 Q타입)
기본 조인
연관 관계 필드끼리 자동 매핑(fk = pk) -> 연관관계 없이 조인하려면 세타조인 사용하기 궁금하면 검색
/**
* 팀 A에 소속된 모든 회원 */
@Test
public void join() throws Exception {
QMember member = QMember.member;
QTeam team = QTeam.team;
List<Member> result = queryFactory
.selectFrom(member)
.join(member.team, team)
.where(team.name.eq("teamA"))
.fetch();
assertThat(result)
.extracting("username")
.containsExactly("member1", "member2");
}
//이렇게 조인하면 member의 fk teamId랑 team의 teamId랑 조인됨
select ...
from member m
join team t on m.team_id = t.id
where t.name = 'teamA'- join() , innerJoin() : 내부 조인(inner join)
- leftJoin() : left 외부 조인(left outer join)
- rightJoin() : rigth 외부 조인(rigth outer join)
- JPQL의 `on` 과 성능 최적화를 위한 `fetch` 조인 제공 다음 on 절에서 설명
✅ 조인 - on 절
ON절을 활용한 조인(JPA 2.1부터 지원)
- 1. 조인 대상 필터링
- 2. 연관관계 없는 엔티티 외부 조인
1. 조인 대상 필터링
예) 회원과 팀을 조인하면서, 팀 이름이 teamA인 팀만 조인, 회원은 모두 조회
/**
* 예) 회원과 팀을 조인하면서, 팀 이름이 teamA인 팀만 조인, 회원은 모두 조회
* JPQL: SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'teamA'
* SQL: SELECT m.*, t.* FROM Member m LEFT JOIN Team t ON m.TEAM_ID=t.id and
t.name='teamA'
*/
@Test
public void join_on_filtering() throws Exception {
List<Tuple> result = queryFactory
.select(member, team)
.from(member)
.leftJoin(member.team, team).on(team.name.eq("teamA"))
.fetch();
for (Tuple tuple : result) {
System.out.println("tuple = " + tuple);
}
}
// team id가 1인 경우에만 출력 (id = 1의 team.name = "teamA")참고 : 내부조인이면 where로 해결하자!
2. 연관관계 없는 엔티티 외부 조인
예)회원의 이름과 팀의 이름이 같은 대상 외부 조인
/**
* 2. 연관관계 없는 엔티티 외부 조인
* 예) 회원의 이름과 팀의 이름이 같은 대상 외부 조인
* JPQL: SELECT m, t FROM Member m LEFT JOIN Team t on m.username = t.name
* SQL: SELECT m.*, t.* FROM Member m LEFT JOIN Team t ON m.username = t.name */
@Test
public void join_on_no_relation() throws Exception {
em.persist(new Member("teamA"));
em.persist(new Member("teamB"));
List<Tuple> result = queryFactory
.select(member, team)
.from(member)
.leftJoin(team).on(member.username.eq(team.name))
.fetch();
for (Tuple tuple : result) {
System.out.println("t=" + tuple);
}
}
// Member는 전부다 반환 Team은 TeamName과 MemberName이 같은 경우 반환주의! 문법을 잘 봐야 한다.leftJoin() 부분에 일반 조인과 다르게 엔티티 하나만 들어간다.
✅ 서브 쿼리
com.querydsl.jpa.JPAExpressions 사용서울 쿼리 eq사용
/**
* 나이가 가장 많은 회원 조회 */
@Test
public void subQuery() throws Exception {
QMember memberSub = new QMember("memberSub");
List<Member> result = queryFactory
.selectFrom(member)
.where(member.age.eq(
JPAExpressions
.select(memberSub.age.max())
.from(memberSub)
))
.fetch();
assertThat(result).extracting("age")
.containsExactly(40);
}
스태틱 Import 사용 가능
import static com.querydsl.jpa.JPAExpressions.select;
from절에는 서브쿼리 불가하다
-> 해결 방안 1. 2번 불리한다. 2. 서브쿼리를 join으로 변경 (가능하다면)
✅ 프로젝션과 결과 반환 - 기본
프로젝션: select 대상 지정
결과 반환 값이 1개면 타입을 명확하게 지정가능.
둘 이상이면 튜플이나 DTO조회
결과를 DTO로 생성할 때 3가지 방법이 있음 v
- 프로퍼티 접근 - Setter
- 필드 직접 접근
- 생성자 사용 (@QueryProjection) @QueryProjection 키워드 생성자 -> @QueryProjection -> QDTO 생성 확인
✅ 동적 쿼리 - BooleanBuilder 사용
동적 쿼리를 해결하는 두가지 방식
- BooleanBuilder
- Where 다중 파리미터 사용
BooleanBuilder 사용
@Test
public void 동적쿼리_BooleanBuilder() throws Exception {
String usernameParam = "member1";
Integer ageParam = 10;
List<Member> result = searchMember1(usernameParam, ageParam);
Assertions.assertThat(result.size()).isEqualTo(1);
}
private List<Member> searchMember1(String usernameCond, Integer ageCond) {
BooleanBuilder builder = new BooleanBuilder();
if (usernameCond != null) {
builder.and(member.username.eq(usernameCond));
}
if (ageCond != null) {
builder.and(member.age.eq(ageCond));
}
return queryFactory
.selectFrom(member)
.where(builder)
.fetch();
}
Where 다중 파라미터 사용
@Test
public void 동적쿼리_WhereParam() throws Exception {
String usernameParam = "member1";
Integer ageParam = 10;
List<Member> result = searchMember2(usernameParam, ageParam);
Assertions.assertThat(result.size()).isEqualTo(1);
}
private List<Member> searchMember2(String usernameCond, Integer ageCond) {
return queryFactory
.selectFrom(member)
.where(usernameEq(usernameCond), ageEq(ageCond))
.fetch();
}
private BooleanExpression usernameEq(String usernameCond) {
return usernameCond != null ? member.username.eq(usernameCond) : null;
}
private BooleanExpression ageEq(Integer ageCond) {
return ageCond != null ? member.age.eq(ageCond) : null;
}- where` 조건에 `null` 값은 무시된다.
- 메서드를 다른 쿼리에서도 재활용 할 수 있다.
- 쿼리 자체의 가독성이 높아진다.
조합 가능 - null 체크는 주의해서 처리해야함.
private BooleanExpression allEq(String usernameCond, Integer ageCond) {
return usernameEq(usernameCond).and(ageEq(ageCond));
}
✅ 수정, 삭제 벌크 연산
JPQL 배치와 마찬가지로 영속성 컨텍스트에 있는 엔티티를 무시하고 실행됨
-> 배치 쿼리를 실행하고 영속성 컨텍스트 초기화 하자!!! 무조건 필수 !!! !!!!
쿼리 한번으로 대량 데이터 수정
long count = queryFactory
.update(member)
.set(member.username, "비회원")
.where(member.age.lt(28))
.execute();
기존 숫자에 1 더하기
long count = queryFactory
.update(member)
.set(member.age, member.age.add(1))
.execute();
쿼리 한번으로 대량 데이터 삭제
long count = queryFactory
.delete(member)
.where(member.age.gt(18))
.execute();
주의: JPQL 배치와 마찬가지로, 영속성 컨텍스트에 있는 엔티티를 무시하고 실행되기 때문에 배치 쿼리를 실행하고 나면 영속성 컨텍스트를 초기화 하는 것이 안전하다.
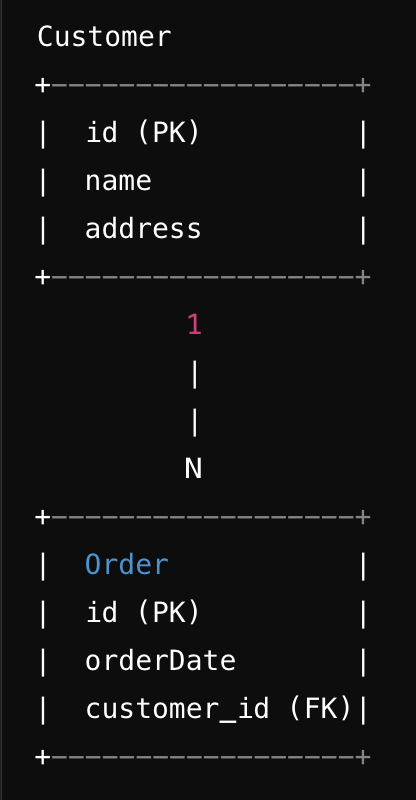
✅ 실제 프로젝트에서 QueryDSL
지금까지 그냥 Test코드에서 쿼리 DSL을 사용했지만 실제 프로젝트에서는 어떻게 Qureydsl을 사용할까?

그림대로 설명해자면 일반적으로 스프링 Data JPA를 사용할 때 리포티지토리 클래스는
JpaRepository 인터페이스를 extends한다.
위 처럼 구성된 세팅에서 custom Interface를 추가하고 그를 구현하는 MemberRepositoryImpl에 Querydsl코드를 추가하면 된다.
단. custom interface의 명칭은 원래 Repository + Custom으로 한다.
위 그림을 참고하여도 이해는 쉬울 것 같다.
✅ 예시 MemberRepositoryImpl
import java.util.List;
import static org.springframework.util.StringUtils.isEmpty;
import static study.querydsl.entity.QMember.member;
import static study.querydsl.entity.QTeam.team;
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final JPAQueryFactory queryFactory;
public MemberRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
//회원명, 팀명, 나이(ageGoe, ageLoe)
public List<MemberTeamDto> search(MemberSearchCondition condition) {
return queryFactory
.select(new QMemberTeamDto(
}
member.id,
member.username,
member.age,
team.id,
team.name))
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()))
.fetch();
private BooleanExpression usernameEq(String username) {
return isEmpty(username) ? null : member.username.eq(username);
}
private BooleanExpression teamNameEq(String teamName) {
return isEmpty(teamName) ? null : team.name.eq(teamName);
}
private BooleanExpression ageGoe(Integer ageGoe) {
return ageGoe == null ? null : member.age.goe(ageGoe);
import java.util.List;
import static org.springframework.util.StringUtils.isEmpty;
import static study.querydsl.entity.QMember.member;
import static study.querydsl.entity.QTeam.team;
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final JPAQueryFactory queryFactory;
public MemberRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
//회원명, 팀명, 나이(ageGoe, ageLoe)
public List<MemberTeamDto> search(MemberSearchCondition condition) {
return queryFactory
.select(new QMemberTeamDto(
}
member.id,
member.username,
member.age,
team.id,
team.name))
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()))
.fetch();
private BooleanExpression usernameEq(String username) {
return isEmpty(username) ? null : member.username.eq(username);
}
private BooleanExpression teamNameEq(String teamName) {
return isEmpty(teamName) ? null : team.name.eq(teamName);
}
private BooleanExpression ageGoe(Integer ageGoe) {
return ageGoe == null ? null : member.age.goe(ageGoe);
/**
* 단순한 페이징, fetchResults() 사용 */
@Override
public Page<MemberTeamDto> searchPageSimple(MemberSearchCondition condition,
Pageable pageable) {
QueryResults<MemberTeamDto> results = queryFactory
.select(new QMemberTeamDto(
member.id,
member.username,
member.age,
team.id,
team.name))
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetchResults();
List<MemberTeamDto> content = results.getResults();
long total = results.getTotal();
return new PageImpl<>(content, pageable, total);
}
* 복잡한 페이징
* 데이터 조회 쿼리와, 전체 카운트 쿼리를 분리 */
@Override
public Page<MemberTeamDto> searchPageComplex(MemberSearchCondition condition,
Pageable pageable) {
List<MemberTeamDto> content = queryFactory
.select(new QMemberTeamDto(
member.id,
member.username,
member.age,
team.id,
team.name))
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long total = queryFactory
.select(member)
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()))
.fetchCount();
return new PageImpl<>(content, pageable, total);
}
✅ CountQuery최적화
count 쿼리가 생략 가능한 경우 생략해서 처리
- 페이지 시작이면서 컨텐츠 사이즈가 페이지 사이즈보다 작을 때
- 마지막 페이지 일 때 (offset + 컨텐츠 사이즈를 더해서 전체 사이즈 구함, 더 정확히는 마지막 페이지이면 서 컨텐츠 사이즈가 페이지 사이즈보다 작을 때)
JPAQuery<Member> countQuery = queryFactory
.select(member)
.from(member)
.leftJoin(member.team, team)
.where(usernameEq(condition.getUsername()),
teamNameEq(condition.getTeamName()),
ageGoe(condition.getAgeGoe()),
ageLoe(condition.getAgeLoe()));
return new PageImpl<>(content, pageable, total);
return PageableExecutionUtils.getPage(content, pageable,
countQuery::fetchCount);
✅ 정렬
정렬을 Pagealble Sort기능을 조금만 복잡해져도 사용하기 힘듦 파라미터로 받아서 하자!
// 정렬 로직 생성
private OrderSpecifier<?> getSort(QGoodsEntity goods, QBidHistoryEntity bid, String sort) {
if ("priceAsc".equalsIgnoreCase(sort)) {
return goods.buyNowPrice.asc();
} else if ("priceDesc".equalsIgnoreCase(sort)) {
return goods.buyNowPrice.desc();
} else if ("currentPriceAsc".equalsIgnoreCase(sort)) {
return currentBidPriceExpr(goods, bid).asc();
} else if ("currentPriceDesc".equalsIgnoreCase(sort)) {
return currentBidPriceExpr(goods, bid).desc();
} else if ("latest".equalsIgnoreCase(sort)) {
return goods.createdAt.desc();
}
return goods.createdAt.desc();
}
//정렬 로직 적용
OrderSpecifier<?> orderSpecifier = getSort(goods, bid, sort);
List<org.example.auctify.entity.Goods.GoodsEntity> entityList = queryFactory
.selectFrom(goods)
.leftJoin(like).on(
like.goods.goodsId.eq(goods.goodsId)
.and(like.user.userId.eq(userId))
).fetchJoin()
.where(builder)
.orderBy(orderSpecifier)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
✅ 정리
!!김영한 강사님의 Querydsl강의를 듣고 정리했습니다.!!
간단하게 자주 쓰일만한 것들을 정리했다. 나중에 프로젝트를 진행하게 된다면 이 글을 참고해서
Querydsl을 리마인드 하고 진행할 것 같다.
'JPA' 카테고리의 다른 글
| QueryDSL 소개, 설정 방법, 그리고 실사용 (0) | 2025.03.30 |
|---|---|
| 실전! 스프링 데이터 JPA 강의 정리 (0) | 2025.02.12 |
| 실전! 스프링 부트와 JPA 활용1 강의 정리 (0) | 2025.02.05 |
| [에러정리] TransientObjectException : save the transient instance before flushing 에러 (0) | 2025.02.04 |
| JPA 양방향 연관관계의 주인 (0) | 2025.02.01 |